Getting started with flempar
By Evelien Willems, Frederik Heylen
Introduction
The Flemish Parliament makes its database available via web services: http://ws.vlpar.be/e/opendata/api. These data are open and free to use without restrictions. The flempar R-package is made for querying the web API. It parses the API responses and transforms JSON into a useful object (i.e. data frame) for the end-user.
This R-package is the result of a collaboration between Wouter Van Dooren, Evelien Willems, both from the Department of Political Science at the University of Antwerp , and Frederik Heylen, founder of Datamarinier.
In this series of blog posts, we are going to use the flempar package to collect and analyze:
- Key characteristics of Flemish members of parliament (MPs):
get_mp() - Parliamentary work, including speeches and documents:
get_work()
We guide you through several specific research questions for each of these two functions to demonstrate the package’s various applications and showcase the wealth of available data. After going through all blog posts, you will be able to work out how to extract other data suited to your particular research questions from the API of the Flemish Parliament. But first things first, let’s get started!
Download and installation
You can install the flempar package from the GitHub account of the Political Science Department of the University of Antwerp, https://github.com/PolscienceAntwerp/flempar. Mac users will also need to install Xcode. If you run into any trouble during the installation, check our troubleshooter.
require(devtools)
install_github("PolscienceAntwerp/flempar")
We then load the flempar package along with the tidyverse suite of R packages to manipulate the data and visualize some results. Additionally, we load in data.table, making working with data frames easier (more info here).
library(flempar)
library(dplyr)
library(tidyr)
library(tibble)
library(ggplot2)
library(stringr)
library(data.table)
In case you don’t have these extra R-packages already installed. Run the following code first, then run the above chunk of code.
install.packages("dplyr")
install.packages("tidyr")
install.packages("tibble")
install.packages("ggplot2")
install.packages("data.table")
First try out
Now, let’s test whether the installation worked! You can try running the get_mp() function with its default options, specifying no parameters. This delivers you the demographics of the current MPs. At the moment of writing this blog post, this comprises all MPs seating in the 2019-2024 legislature.
get_mp()
When making calls, you get feedback about the number of calls that will be made. Depending on the number of calls, this might take a couple of seconds to several minutes. If the call succeeds, the exact time needed to do so gets displayed.
In this regard, the build-in use_parallel=TRUE argument is one of the main advantages of using our flempar package. This functionality ensures that instead of serial processing (i.e. one batch after the other), your computer is told to divide the work among its processing cores to execute the work in parallel (i.e. simultaneously); which significantly speeds up the data retrieving process. So, in almost all instances, you will want keep the default-setting use_parallel=TRUE, which makes it unnecessary to explicitely specificy this as a parameter in the function.
Example of feedback:
Making 124 calls.
Made 124 calls in 143.7 seconds.
What you get is a simple overview of the data. This is how the output looks like:
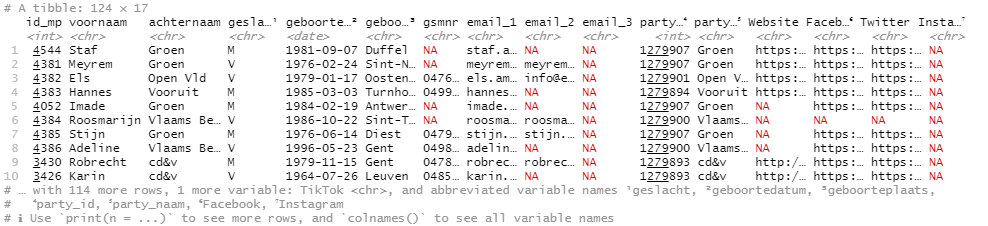
Default output `get_mp()`
So on to the get_work()function. In contrast to the get_mp function, you always need to specify a date range using the following arguments:
- date_range_from: the start date YYYY-MM-DD
- date_range_to: the end date YYYY-MM-DD
As an enormous amount of data can be retrieved through the get_work() function, it is highly recommended to test your query on a limited date range before expanding the date range to comprise multiple months to years. As no other parameters are specified, you end up with the default data, namely info about plenary debates.
get_work(date_range_from="2022-03-01"
, date_range_to="2022-03-15")
Again, you get some performance feedback about the calls being made and a first rough look at the output.
That’s it, you’ve now covered the basics of the flempar package!